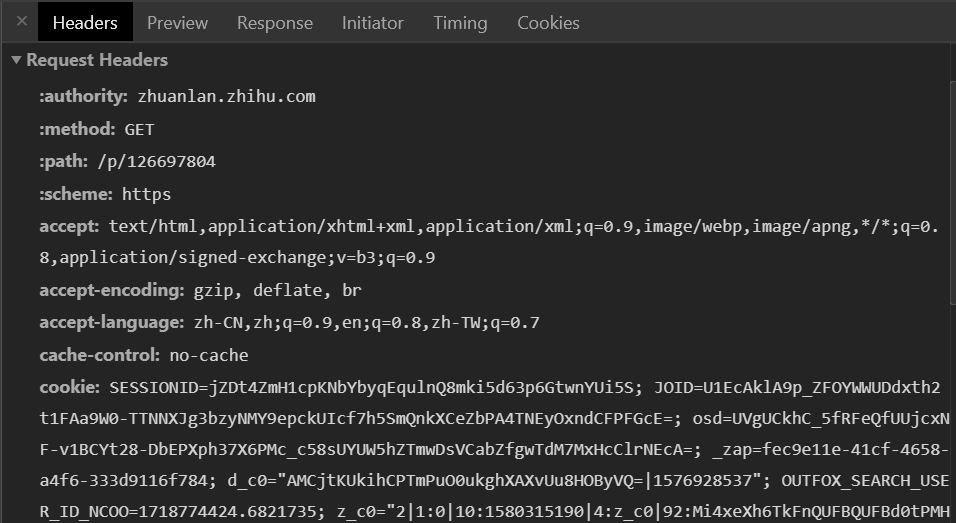
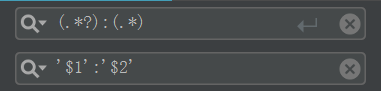
如果以同样的select rule 应用于所有页面,最后的结果却是部分数据缺失,99%的情况都是这些页面上要么没有你的rule中构造好的id or class,要么就是rule中的id和class所应用在的元素和其他页面不一样。
nth-of-type与:nth-child
nth-of-type被Beautifulsoup支持,后者不被支持
select规则书写规范
1 2 3 4 5 6
""" The combinator 'x' at postion xx, must have a selector before it 此错误不是任何时候都会报错,但是要注意书写规范,在select rule不要多空格或者其他乱七八糟的字符在 """ '.mw-parser-output > ul:nth-of-type({}) > li a' #正确写法 '.mw-parser-output > ul:nth-of-type({}) > li a' #多了一个空格报错
defis_chinese(string): """ check whether the string includes the Chinese param: string """ for ch in string: ifu'\u4e00' <= ch <= u'\u9fff': returnTrue
returnTrue
处理url中的sharp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# 处理url中的#号 # 把#(sharp)转为%23 def sharp_fix(url): """ the sharp (#) will incur some troubles in url param: url
A slice of [:] means the entire list. And, [:]=is quite different from =
1 2 3 4 5 6 7 8 9 10 11 12
>>> original = [1, 2, 3] >>> other = original >>> original[:] = [0, 0] # changes the contents of the list that both # original and other refer to >>> other # see below, now you can see the change through other [0, 0]
>>> original = [1, 2, 3] >>> other = original >>> original = [0, 0] # original now refers to a different list than other >>> other # other remains the same [1, 2, 3]
lst[:] not followed by an = calls __getitem__, while lst[:] = calls __setitem__