Python笔记与备忘录
Python笔记与备忘录
本页面记录本人在编写python项目时遇到的所有陷阱和技巧 (update forever)
爬虫篇
坑、陷阱 / Pitfall
headers构造空格
从浏览器开发者工具复制下来的headers一定要注意把空格消除。不然会被视为invalid headers.
selector规则构造
如果以同样的select rule 应用于所有页面,最后的结果却是部分数据缺失,99%的情况都是这些页面上要么没有你的rule中构造好的id or class,要么就是rule中的id和class所应用在的元素和其他页面不一样。
nth-of-type与:nth-child
nth-of-type被Beautifulsoup支持,后者不被支持
select规则书写规范
1
2
3
4
5
6"""
The combinator 'x' at postion xx, must have a selector before it
此错误不是任何时候都会报错,但是要注意书写规范,在select rule不要多空格或者其他乱七八糟的字符在
"""
'.mw-parser-output > ul:nth-of-type({}) > li a' #正确写法
'.mw-parser-output > ul:nth-of-type({}) > li a' #多了一个空格报错中文字符显示不全
原因在于网页大都采用UTF-8字符集,该字符集缺字严重,连国务院2013年8月19日公布的8105个通用规范汉字(均为简体汉字)都不能全部显示出来,共缺249个汉字,复其中4个二级字,245个三级字。
一种可行的解决方法是:以维基百科为例,如果你爬取的是简体页面,那么你可以尝试寻找该页面是否有繁体中文版本,繁体字被爬取下来的时候是可以正常显示的
Url中的#
在scrapy爬虫框架中会自动过滤掉#后面的内容,网络请求的时候“#”后面的参数会被忽略,解决方法T-4。
技巧 / Tech
headers构造
构造请求头(headers)时,可以直接从chrome的调试工具处复制真实的请求头
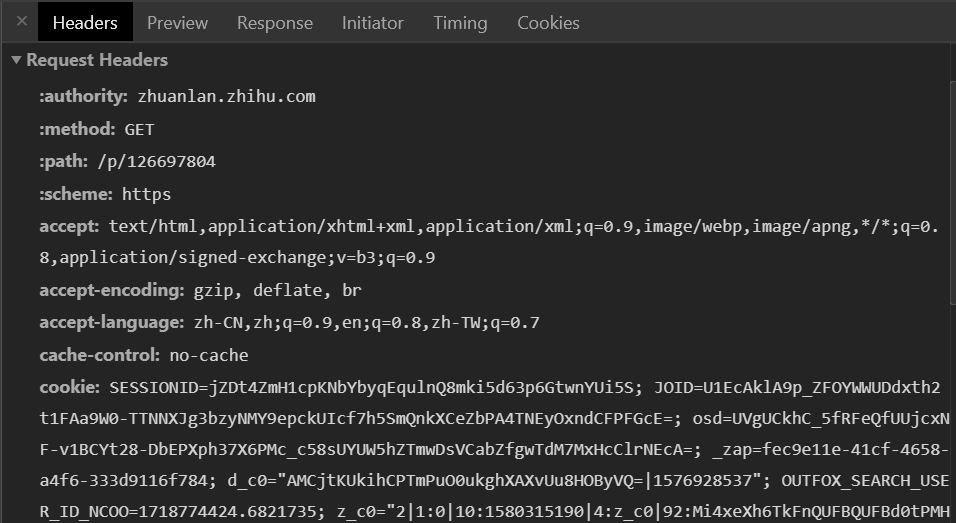
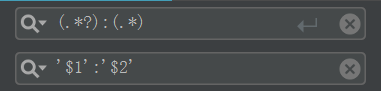
然后此时还需要一点小微操就可以正确使用,以Pycharm为例,按Ctrl+R调出Regex匹配模式
1
2
3分别输入
(.*?):(.*)
'$1':'$2'此时带有正确引号包裹的一个个headers键值对就构造好了。
url中文处理
1
2
3
4
5
6
7
8
9urllib.parse.unquote
# 解码
print(urllib.parse.unquote('%B1%E0%C2%EB%BF%D3%B5%F9'))
坑爹
# 编码
urllib.parse.quote
print(urllib.parse.quote('坑爹'))
'%B1%E0%C2%EB%BF%D3%B5%F9'判断字符串中是否有中文字符
1
2
3
4
5
6
7
8
9
10def is_chinese(string):
"""
check whether the string includes the Chinese
param: string
"""
for ch in string:
if u'\u4e00' <= ch <= u'\u9fff':
return True
return True处理url中的sharp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 处理url中的#号
# 把#(sharp)转为%23
def sharp_fix(url):
"""
the sharp (#) will incur some troubles in url
param: url
"""
if url.find('#') >= 0:
strs = url.split('#')
if is_chinese(strs[1]):
fix = urllib.parse.quote(strs[1])
fix = strs[0] + '%23' + fix
return fix
return url
return urlList篇
[:]
[:]=与直接赋值(=)的区别
A slice of
[:]means the entire list. And,[:]=is quite different from=1
2
3
4
5
6
7
8
9
10
11
12original = [1, 2, 3]
other = original
original[:] = [0, 0] # changes the contents of the list that both
# original and other refer to
other # see below, now you can see the change through other
[0, 0]
original = [1, 2, 3]
other = original
original = [0, 0] # original now refers to a different list than other
other # other remains the same
[1, 2, 3]lst[:]not followed by an=calls__getitem__, whilelst[:] =calls__setitem__